글에서 질문을 만드는 인공지능 (Question Generation with KoBART)
글의 원본은 다음 링크입니다. 물론 제가 쓴 글입니다. 작성일자는 22년 6월 30일입니다. 내나이 고3때 ..
rycont/kobart-question-generation-kit (github.com)
썸네일은 Bing image creator로 제작되었습니다. 프롬프트는 [Question and Answering, paper, speech bubble, robot, Vector Illustration, Hype, App icon]
Notebook 코드는 Kaggle에 업로드되어있습니다 🙏
Pretrained Model은 Huggingface에 업로드되어있습니다 👌
독자의 읽기 능력 수준을 평가하는 프로그램을 개발하기 위해, 한국어 문단을 제대로 이해했는지 확인할 수 있는 질문을 생성하는 인공지능을 구현하고자 합니다.
예상 동작
- 입력
경복궁의 주요건물 위치를 보면 궁 앞면에 광화문이 있고 동·서쪽에 건춘·영추의 두 문이 있으며 북쪽에 신무문이 있다. 궁성 네 귀퉁이에는 각루가 있다. 광화문 안에는 흥례문이 있고 그 안에 개천 어구가 있어 서쪽에서 동쪽으로 흘러나간다.어구에 돌다리인 금천교, 곧 영제교가 놓여 있고 다리를 건너면 근정문이 있으며 문을 들어서면 정전인 근정전이 이중으로 높이 쌓은 월대 위에 우뚝 솟아 있다.
- 출력
흥례문 안에 있는 개천어구는 어느 방향으로 흐르나요?
언어모델 선정
기본적으로는 문단을 질문으로 변환하는 모델이기 때문에, Seq2seq를 활용하였습니다. 사전학습된 한국어 Seq2seq 모델에는 ETRI에서 공개한 KeT5(한국어 + 영어), SKT에서 공개한 KoBART(한국어)가 있는데, 그중 활용 예제가 더 풍부한 BART를 사용하였습니다.
haven-jeon/KoBART-chatbot 레포지토리의 코드를 수정하여 제작하였습니다.
데이터셋 준비
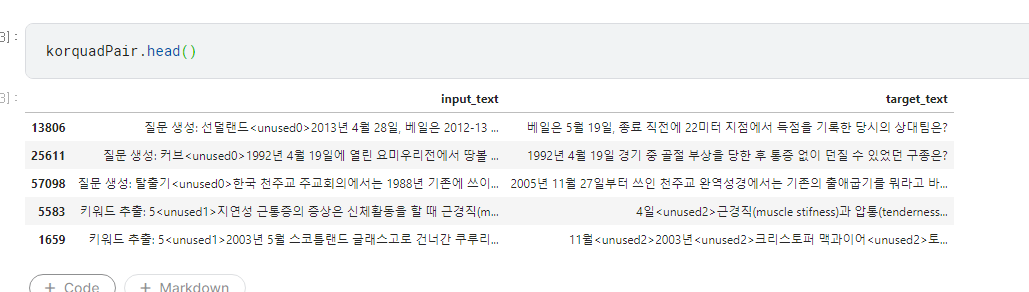
인공지능 모델을 학습하기 위해서는, 구현을 원하는 동작과 일치하는 데이터셋이 필요합니다. 문단과 질문이 연결되어있는 데이터셋이 어떤 것이 있을지 생각해보았고, 여러 데이터셋들중 Korquad 1.0이 가장 적당하다고 생각하였습니다.
학습!
데이터셋을 아래와 같이 전처리하여 학습하였습니다
- 입력: 경복궁의 주요건물 위치를 보면 궁 앞면에 광화문이 있고 동·서쪽에 건춘·영추의 두 문이 있으며 북쪽에 신무문이 있다. 궁성 네 귀퉁이에는 각루가 있다. 광화문 안에는 흥례문이 있고 그 안에 개천 어구가 있어 서쪽에서 동쪽으로 흘러나간다.어구에 돌다리인 금천교, 곧 영제교가 놓여 있고 다리를 건너면 근정문이 있으며 문을 들어서면 정전인 근정전이 이중으로 높이 쌓은 월대 위에 우뚝 솟아 있다.
- 출력: 흥례문 안에 있는 개천어구는 어느 방향으로 흐르나요?
Korquad는 한 문단에 여러개의 질문이 달려있습니다. 질문별로 각각의 데이터를 생성해서, 전체 데이터셋에는 동일한 입력에 다른 출력이 매칭되어있는 데이터가 존재했습니다.
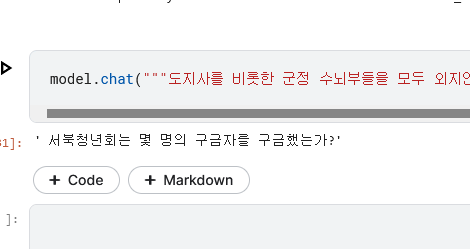
테스트데이터 출처: 한국민족문화대백과사전의 "제주 4.3 사건" 문서
입력:
도지사를 비롯한 군정 수뇌부들을 모두 외지인으로 교체했고 응원경찰과 서북청년회원 등을 대거 제주로 파견해 파업 주모자에 대한 검거작전을 벌였다. 검속 한 달 만에 500여 명이 체포됐고, 1년 동안 2,500명이 구금됐다. 서북청년회(이하 ‘서청’)는 테러와 횡포를 일삼아 민심을 자극했고, 구금자에 대한 경찰의 고문이 잇따랐다. 1948년 3월 일선 경찰지서에서 세 건의 고문치사 사건이 발생해 제주사회는 금방 폭발할 것 같은 위기상황으로 변해갔다.
결과:
서북청년회는 몇명의 구금자를 구금하였는가?
데이터셋에 존재하지 않는 문단을 사용하여 눈으로 테스트해보았고, 제법 준수한 결과가 나와주었습니다. 다만 한 가지 문제가 있었는데, 여러번 실행했을 때에 서로 다른 결과가 나오는 것을 기대하고 한 입력에 서로 다른 출력이 매칭되는 데이터셋을 구성하였지만, 예상과는 다르게 같은 입력에는 항상 똑같은 질문만 나와주었습니다. 그래서 한 문단에 한 질문만 생성이 되었는데, 이를 보완하고 한 문단에서 여러 질문을 생성하기 위해 다음과 같이 데이터셋을 수정하였습니다.
입력: 경복궁의 주요건물 위치를 보면 궁 앞면에 광화문이 있고 동·서쪽에 건춘·영추의 두 문이 있으며 북쪽에 신무문이 있다. 궁성 네 귀퉁이에는 각루가 있다. 광화문 안에는 흥례문이 있고 그 안에 개천 어구가 있어 서쪽에서 동쪽으로 흘러나간다. 어구에 돌다리인 금천교, 곧 영제교가 놓여 있고 다리를 건너면 근정문이 있으며 문을 들어서면 정전인 근정전이 이중으로 높이 쌓은 월대 위에 우뚝 솟아 있다.
원하는 출력:
1. 경복궁의 앞에는 무슨 건물이 있나요?
2. 근정문을 지나면 어디로 이동하게 되나요?
3. 개천어구는 어느 방향으로 흐르나요?
이렇게 한 문단에 여러 질문이 매칭되도록 확실하게 데이터셋을 구성해주었지만, 예상과는 다른 결과가 나왔습니다.

입력: 3<unused0>경복궁의 주요건물 위치를 보면 궁 앞면에 광화문이 있고 동·서쪽에 건춘·영추의 두 문이 있으며 북쪽에 신무문이 있다. 궁성 네 귀퉁이에는 각루가 있다. 광화문 안에는 흥례문이 있고 그 안에 개천 어구가 있어 서쪽에서 동쪽으로 흘러나간다. 어구에 돌다리인 금천교, 곧 영제교가 놓여 있고 다리를 건너면 근정문이 있으며 문을 들어서면 정전인 근정전이 이중으로 높이 쌓은 월대 위에 우뚝 솟아 있다.
원하는 출력:
1. 경복궁의 앞에는 무슨 건물이 있나요?
2. 근정문을 지나면 어디로 이동하게 되나요?
3. 개천어구는 어느 방향으로 흐르나요?
Unused Token을 사용해서 사용자가 원하는 질문 갯수를 알려주는 방법도 시도해보았지만, 힌트를 주지 않은 데이터셋과 거의 동일한 결과가 나왔습니다. 그냥.. 똑같은 질문을 몇번 반복할 지 알려주는 힌트가 된것같습니다.
학습 방법의 전환
Korquad는 한 지문에 여러개의 질문 / 답변이 매칭되어있는 데이터셋입니다. 주어진 자료를 적극적으로 활용하여, 답변도 학습에 활용하면 어떨까?싶어서, 다음과 같은 데이터셋을 고안해보았습니다.
입력: 정답<unused0>문단
출력: 주어진 정답에 알맞는 질문
이렇게 구성하면 같은 입력에 대해서는 똑같은 출력이 나오는 것을 보장할 수 있고, 또한 명시적으로 정답을 먼저 알려주기 때문에 더 명확한 질문을 생성할 수도 있다는 기대도 들었습니다.
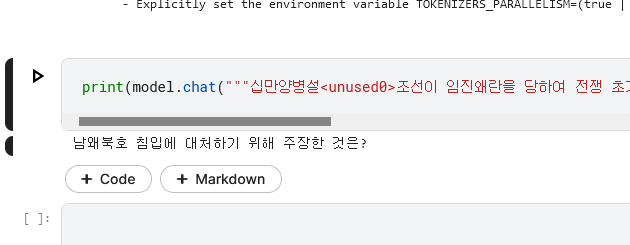
기대한 것 이상의 결과물이 나와주었습니다. 한 지문에서도 서로 다른 정답을 입력했을 때에 각 정답에 올바른 질문을 적절하게 생성하는 모습을 보여주었습니다. 만약 지문에서 정답 후보를 추출해내는 모델을 개발할 수 있다면, 정답 생성 모델과 질문 생성 모델을 파이프라인으로 연결해서 질문생성 태스크를 잘 수행해낼 수 있겠다는 생각이 들었습니다.
연구 과정에서 얻어낸 몇가지 재밌는 결과가 있습니다.
입력: 방탄소년단<unused0>임진왜란은 1592년(선조 25)부터 1598년까지 2차에 걸쳐서...
출력: 조선이 임진왜란을 당하여 국력이 쇠약해진 것을 막기 위해 만든 단체는?
질문과 전혀 관련없는 정답을 알려줘도 그럴싸한 질문을 생성하고
입력: 임진왜란은 1592년(선조 25)부터 1598년까지 2차에 걸쳐서...
출력: 1592년부터 1598년 까지 2차에 걸쳐서 우리 나라에 침입한 일본과의 전쟁은?
정답을 알려주지 않으면 지문 전체를 요약하는 질문을 생성합니다.
키워드 생성 모델
다음과 같은 데이터셋을 구성하였습니다.
입력: [키워드갯수]<unused0>[입력문단]
출력: [키워드1] [키워드2] ...
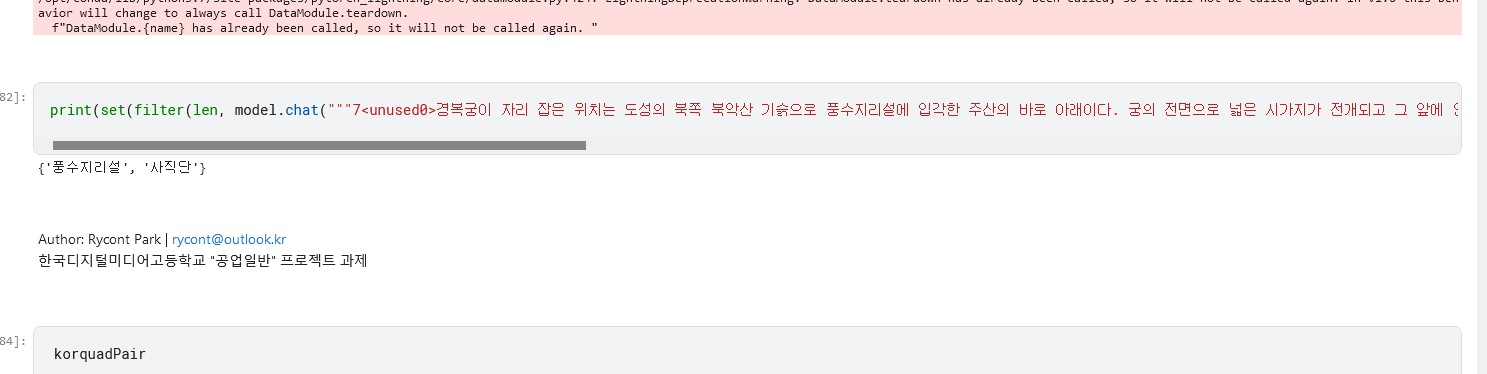
생성이 잘 되긴 했지만, 여러 예제를 돌려보았을 때 어색한 부분이 있어서 데이터셋 구조를 수정해보기로 하였습니다.
출력: [키워드1]<unused1>[키워드2]<unused1>[키워드3]...

의도에 맞게 훌륭한 결과를 추출해 내는 것을 확인하였습니다. 이렇게 안정적인 두 개의 모델을 학습시켰지만, 하나의 소규모 서버에서 최소 두개의 인공지능 모델을 구현하기에는 부담이 있었습니다. KoBART는 모델 하나당 약 500MB 내외의 비교적 가벼운 용량을 가지고 있긴 했지만, 한 BART 모델에서 여러 태스크를 수행하는 Multitask를 도입하기로 하였습니다.
하나의 모델로 여러 태스크를 처리하기
T5에서는 Prefix를 통해 Multitask를 수행해였습니다. 데이터셋에 여러 태스크를 혼합해서 구성해두고, 입력데이터의 맨 앞에 수행할 태스크를 알려주는 방식으로 멀티태스크를 구현합니다.
위와 같이 질문 생성, 키워드 추출 이라는 태스크 라벨을 입력 텍스트 앞에 붙혀주었으며, 각 태스크에 알맞는 출력값을 입력해주었습니다. 동일한 지문이라도 서로 다른 두개의 태스크에 대해 모두 데이터셋이 생성되도록 하여, 동일한 지문에서 여러 태스크를 수행하는 방법도 함께 학습시켰습니다. 다만 키워드 추출은 한 지문에서 한 데이터만 생성이 가능하고, 질문 생성은 한 지문당 여러개가 가능하였기 때문에, 태스크별 데이터셋 갯수가 불균형했습니다.
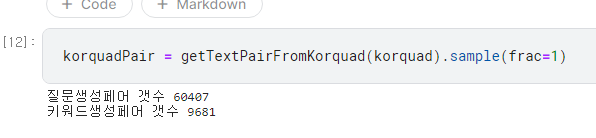
학습 편향을 방지하기 위해 질문생성 태스크의 갯수를 키워드 생성 태스크의 갯수로 맞춰주었습니다.
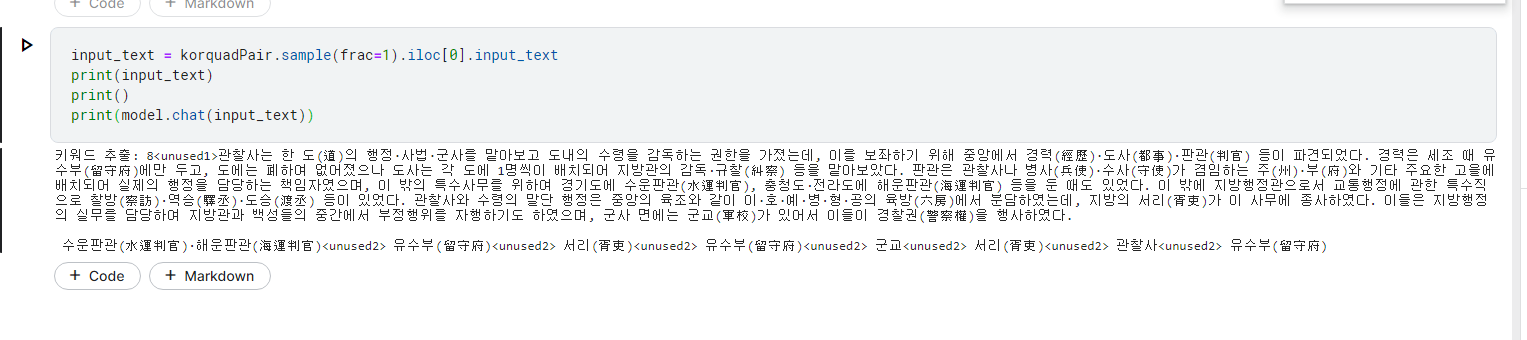
키워드 추출도, 질문 생성도 모두 문제 없이 잘 작동하는 것을 확인했습니다.
혹시 데이터를 더 추가한다면 여러 상황에 더 잘 적응할 수 있지 않을까 하여 KLUE 데이터셋을 추가해보았으나, KLUE는 대부분의 지문에 하나의 질문만 매칭되어 있어서 한 지문에서 추출되는 키워드의 갯수가 거의 하나로 제한되었으며, 이로 인해 키워드 추출 태스크의 성능이 하락하는 모습을 보여서 최종적으로는 Korquad 1 데이터로만 학습하였습니다.
결과물

한국민족문화대백과사전 "임진왜란" 문서
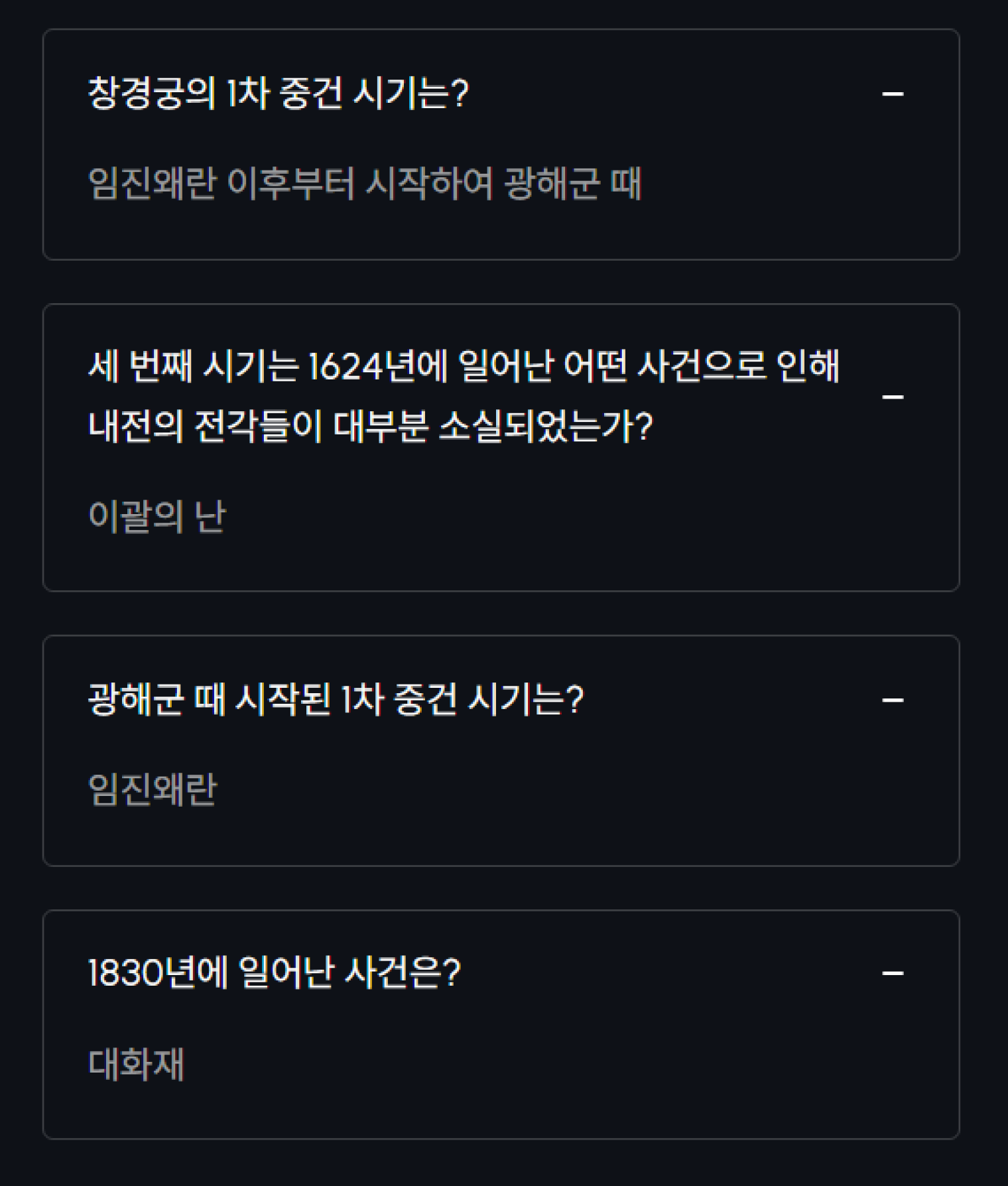
한국민족문화대백과사전 "창경궁" 문서
나무위키 "국립과학수사연구원" 문서