Few-shot으로 특정 발화자의 문체를 복사하는 언어모델 개발하기
한양대학교, 디지스트 학부 입시 특기자전형에 제출했던 보고서를 공개합니다. 원본의 작성일자는 2022년 8월 28일 ~ 10월 14일입니다.
요약
이전까지의 문체 전이 모델은 많은 양의 문체 데이터를 통해 모델을 튜닝하거나, 병렬데이터가 필요하거나, 거대한 언어모델이 필요하다는 한계가 있습니다. 본 보고서에서 제시하는 구조는 이런 한계에서 벗어나, 크지 않은 언어모델에서도 몇 개의 문체 예시만으로 대상 문장에 문체를 전이할 수 있습니다. Non parallel few shot으로 In-context Inference가 가능하기 때문에, 사전에 학습된 몇몇 문체 스타일이 아닌 개개인의 문체를 전이하여 개인화된 온디바이스 자동응답기, 혹은 캐릭터 대화 챗봇에서 문체를 유지하는데 사용할 수 있습니다. 모델 구현에는 사전학습된 한국어 BART와 GPT를 사용하였습니다.
KoBART Seq2seq 모델 하나만으로 태스크를 구현하고자 하였으나, 문장 → 문장 태스크에 강한 BART 모델의 특성상 여러 입력이 혼합되어있는 Few-shot는 학습을 잘 하지 못하는 모습을 보였습니다. 태스크를 문체 제거와 병렬 문체 전이의 두 단계로 나누고, 각 태스크의 특성에 맞게 문체 제거에는 BART를, 병렬 문체 전이에는 GPT를 사용하였습니다. 문체 전이에서 In-context learning을 적용하기 위해, GPT의 병렬 문체 전이 태스크를 Auto Regressive하게 구성하였습니다. 이러한 과정을 통해, 이루고자 하는 목표였던 “몇 개의 예시만으로 학습 없이 문체를 복사하는 언어 모델”을 성공적으로 개발할 수 있었습니다. 개인으로 혼자 진행한 연구이며, 타인과 직접적인 협업은 하지 않았습니다.
들어가며
최근 가상인간을 필두로 하여 소통 가능한 디지털 개체가 주목받고 있습니다. 이러한 관심은 가상 미디어 생성 기술의 발전을 배경으로 한 “몰입가능한” 개체를 만드는 기술을 기반으로 하고 있습니다. 대화형 디지털개체는 크게 외형 렌더링, TTS, 대화엔진 등으로 구현되며, 각각의 도메인에 캐릭터의 페르소나가 올바르게 녹아들어야 사용자는 개체에 더 몰입할 수 있게 됩니다. 본 연구에서 이 도메인들중 대화엔진에서의 페르소나 유지에 대해 알아보기 위해, 딥러닝 기술을 활용하여 몇 개의 대화 프롬프트로 문체를 추출하고 스타일에 기반한 대화 문장를 만드는 방법에 대해 탐구해보려고 합니다.
기존 연구성과
딥러닝을 활용하여 문체를 변환하는 모델은 지금까지 활발하게 연구되어왔습니다.
학술 논문
오토인코더와 적대 네트워크를 활용한 한국어 문체 변환
특정 문체로 쓰여진 비병렬 말뭉치에 적대적 생성 신경망(GAN)을 적용하여 문체가 덜어진 텍스트를 생성하는 방법으로 병렬코퍼스를 만들어낸 뒤, Seq2seq 모델에 병렬 코퍼스를 투입하여 문체 변환 모델을 만들어낸 연구입니다.
적대적 생성 신경망을 통하여 비병렬 코퍼스에서 문체변환을 수행한 점이 인상적이였습니다. 하지만 생성하고자 하는 문체마다 모델을 별도로 학습해야 한다는 점과, 많은 양의 문체 데이터셋이 필요하다는 부분에 있어서는, 이러한 구조를 적용할 수 있는 분야가 한정적이라는 점을 느꼈습니다.
입력 문장 Noising과 Attention 기반 비교사 한국어 문체 변환
두개의 비병렬 코퍼스 사이에서 Attention 기반의 RNN으로 CycleGAN의 방법론을 구현하여 문체 변환 모델을 만들어낸 연구입니다. RNN의 인코더는 문체와 관계 없이 공통으로 사용하고, 디코더는 문체별로 분리하였습니다. A문체와 B문체가 있을 때, A → B → A를 거쳐서 나온 Cycle Consistency Loss와, A → A를 수행한 Reconstruction Loss를 줄이는 방법으로 학습되었습니다.
RNN 모델을 활용하되 인코더는 공통으로, 디코더는 별개로 사용한 것이 인상깊었습니다. 하지만 첫번째로 소개한 논문과 유사하게 학습된 모델 재활용 불가, 큰 데이터셋 필요 등이 해소되지 않아서 아쉬웠습니다.
기타 연구
텍스트 스타일을 바꾸는 딥러닝 기술
텍스트 스타일을 바꾸는 딥러닝 기술 | 카카오엔터프라이즈 AI Research (kakaoenterprise.github.io)
입력 시퀀스에서 원본 문체를 구성하는 주요 토큰을 생략한 후에, 생략한 토큰을 목적 문체와 유사하도록 채우는 방법론을 사용하였습니다. 먼저 문장의 문체를 판별하는 분류기를 만들고, 문장의 각 토큰들을 한개씩 지워보며 문체 판별 점수 등락에 가장 많이 영향을 끼치는 주요 토큰을 찾아낸 후에, 이 토큰들을 마스킹하고 Seq2seq모델에 투입해서 나온 문장의 문체 판별 점수가 정답에 가까워지도록 학습하였습니다.
본문에서 제시된 긍정 → 부정과 같이 특정 어휘가 문체를 뚜렷하게 구별할 수 있는 환경에서는 적절하게 활용될 수 있겠지만, 목적 문체가 어휘 대체 만으로 구성될 수 없는 상황에서는 적용하기 어렵다는 부분을 단점으로 느꼈습니다.
HyperCLOVA로 만드는 캐릭터 챗봇
HyperCLOVA의 활용 (3) 대화 (naver.com)
HyperCLOVA는 네이버에서 개발한 GPT3 기반의 초대규모 한국어 언어모델입니다. 자사의 컨퍼런스에서 HyperCLOVA를 활용하여 2-shot dialog history를 Context로 입력받아 캐릭터 세계관과 문체를 따라하는 챗봇을 시연하였습니다. Dialog history를 통해 캐릭터의 세계관을 일관적이게 유지할 수 있다는 점, In-context로 맥락을 주입할 수 있다는 점이 인상적이였지만, 원격 서버에서 호스팅되는 초대규모 언어모델을 사용하기 때문에, On-premise 및 Edge device에서 실행할 수 없다는 점이 아쉬웠습니다.
사전학습된 언어모델을 사용한 문체 모사 모델 개발
어떻게 극소량의 데이터만으로 미세조정 없이 문체를 변환하는 모델을 만들 수 있을지 고민해보았습니다. 첫번째로 고안한 모델은 사전학습된 Seq2seq를 활용하는 방법입니다.
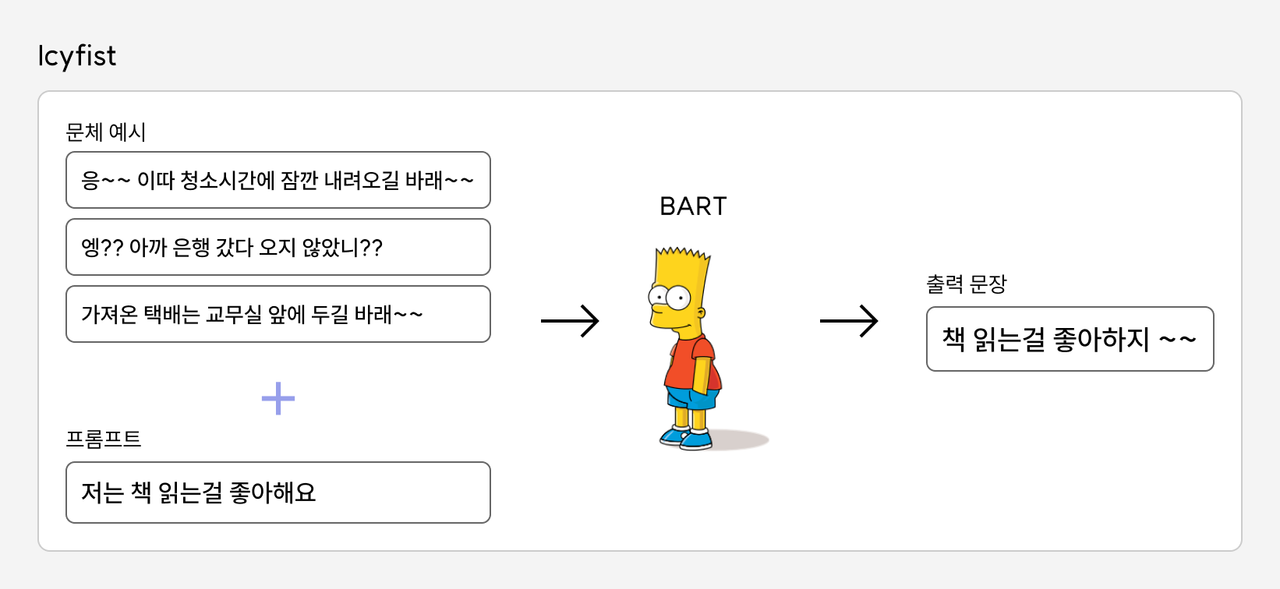
위와 같이 입력시퀀스를 N개의 문체예시와 프롬프트의 결합으로, 출력문장을 변환된 문장으로 삼아서 학습을 시키는 방법을 시도해보았습니다. 모델은 KoBART을, 데이터셋은 스마일게이트의 SmileStyle을 사용하였습니다.
https://github.com/smilegate-ai/korean\_smile\_style\_dataset
SmileStyle은 동일한 대화 내용을 17개 발화 스타일로 변환한 데이터셋입니다. 구체적인 프롬프트 구성은 다음과 같습니다. 이러한 구성을 통해, 앞에서 제시된 문체를 뒤에 입력된 문장에 전이해야한다는 의도를 모델이 학습할 수 있기를 기대하였습니다.
#입력
<unused1> 왜 가지 못하였소?
<unused1> 과인이 나온 대학원이 캘리포니아에 있었소.
<unused1> 한 번 다시 클라리넷을 다시 잡아보고 싶어졌소.
<unused1> 소인께선 주로 어떤 그림을 그리시오?
<unused2> 비까지 오는데 사람도 많으면 찜찜하겠어요.
---
#출력
비까지 오는데 사람도 많으면 많으면
결과는 좋지 않았습니다. 이전에 KoBART에 병렬 문체변환 코퍼스를 지도학습하였을 때에는 훌륭한 성능을 보여주었었어서 이번에도 잘 될것이라고 생각하였지만, 원래 모델의 목적에 맞는 Sequence → Sequence 태스크 이외에서는 의도와 다르게 동작할 수 있다는 부분을 알았습니다.
모델 구조 변경
이러한 태스크에 Seq2seq 모델을 활용하는 것이 적당하지 않다는것을 알았기에, 이번에는 모델의 구조를 변경해서 Auto Regressive Task로 만들어 GPT로 학습해보았습니다. 우선 Task를 다시 모델링하였습니다.
# 프롬프트
<unused0> 왜 가지 못했나요? <unused1> 왜 가지 못하였소?
<unused0> 제가 나온 대학원이 캘리포니아에 있었습니다. <unused1> 과인이 나온 대학원이 캘리포니아에 있었소.
<unused0> 한 번 다시 클라리넷을 다시 잡아보고 싶어졌어요. <unused1> 한 번 다시 클라리넷을 다시 잡아보고 싶어졌소.
<unused0> 당신은 주로 어떤 그림을 그리시나요? <unused1> 소인께선 주로 어떤 그림을 그리시오?
위와 같이 모델의 내부적으로는 병렬코퍼스를 활용하는 방식으로 선회하였습니다. 또한 여기에 문체 문장들에서 자동으로 문체를 제거하는 모델을 개발하여, 실제로 사용할 때에는, 비병렬 Few shot 만으로 작동하도록 구상하였습니다. 우선 이러한 구조가 가능한지 알아보기 위해, 문체 제거 모델을 먼저 구현해보겠습니다.
💡 이 보고서에서 “문체 제거”는 글에서 특징적인 문체를 덜어낸다는 의미로 사용하였습니다. 문체 제거 모델을 통해서 특징적인 문체로 쓰인 글을 일반적인 구어체 어조로 변환하는 모델을 만들 예정입니다.
문체 제거 모델(Unstyler) 구현하기
위의 SmileStyle 데이터셋을 동일하게 사용하였고, 17종류의 병렬코퍼스를 별도의 전처리 없이 바로 BART 모델에 투입하였습니다. 격식어조를 출력 문체로 설정하였고, 격식어조를 제외한 나머지 16개의 문체를 입력 문체로 하였습니다.
# 입력
소인께선 주로 어떤 그림을 그리시오?
---
# 출력
당신은 주로 어떤 그림을 그리시나요?
입출력 데이터를 위와 같이 구성하여, 총 33,323개의 병렬 데이터셋을 만들어 학습시켰습니다. 다만 국문법적으로 올바르지 않은 문장들이 많이 포함되어있는 번역기 말투(Translator)와 안드로이드 말투(Android)는 제거하였습니다. Epochs는 한 번, 최적화함수는 AdamW를 사용하였고, Epoch는 4로 설정하였습니다.
# 제거한 데이터의 예시
**번역기**
반가운. 나는 6마리의 고양이를 소지하고 있다.
**안드로이드**
휴먼. 반갑다. 안드로이드는. 고양이. 6마리. 소유중.
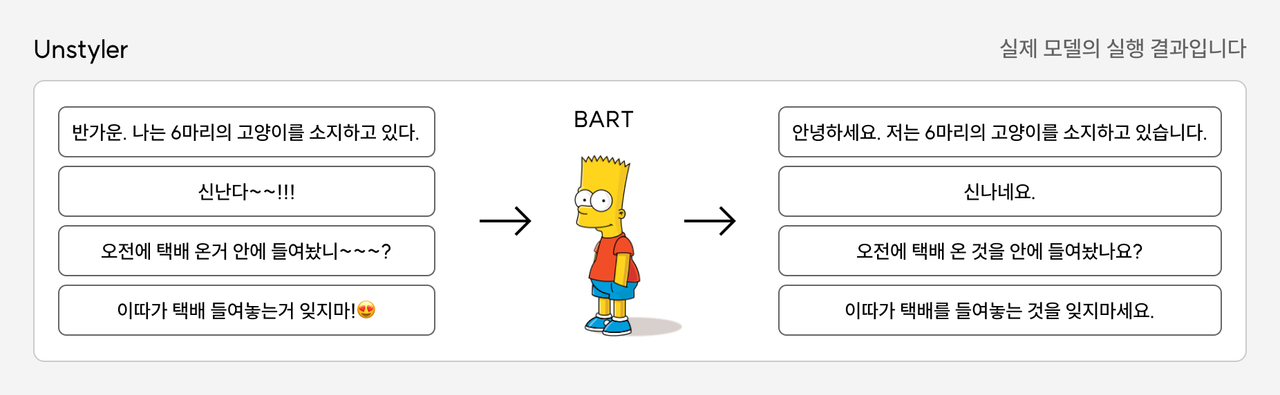
그림에서 볼 수 있다싶이, 제법 성공적인 결과를 얻을 수 있었습니다. 또한 학습데이터로 사용하지 않은 번역기 말투를 테스트해보았을 때에도 문체 제거에 성공하였습니다.
문체 전이 모델(Restyler) 개발
이제 문체 전이 모델(Restyler)을 개발해보겠습니다. 동일하게 SmileStyle 데이터셋을 활용할 예정이고, 입출력 데이터는 다음과 같이 구성하였습니다. 모델 구조 변경 단락에서 언급한 구성과 동일하게, In-context 병렬 데이터셋을 만들었습니다. 모델은 한국어 KoGPT2를 사용하였습니다.
# 프롬프트
<unused0> 왜 가지 못했나요? <unused1> 왜 가지 못하였소?
<unused0> 제가 나온 대학원이 캘리포니아에 있었습니다. <unused1> 과인이 나온 대학원이 캘리포니아에 있었소.
<unused0> 한 번 다시 클라리넷을 다시 잡아보고 싶어졌어요. <unused1> 한 번 다시 클라리넷을 다시 잡아보고 싶어졌소.
<unused0> 당신은 주로 어떤 그림을 그리시나요? <unused1> 소인께선 주로 어떤 그림을 그리시오?

이 또한 KoGPT의 강력한 성능에 힘입어, 제법 그럴듯한 결과물을 볼 수 있었습니다. 제거모델과 전이모델을 결합한 전체 모델의 구조는 다음과 같습니다. 오른쪽 위 초록색이 유저의 인풋이고, 오른쪽 아래 파란색이 최종 출력입니다.
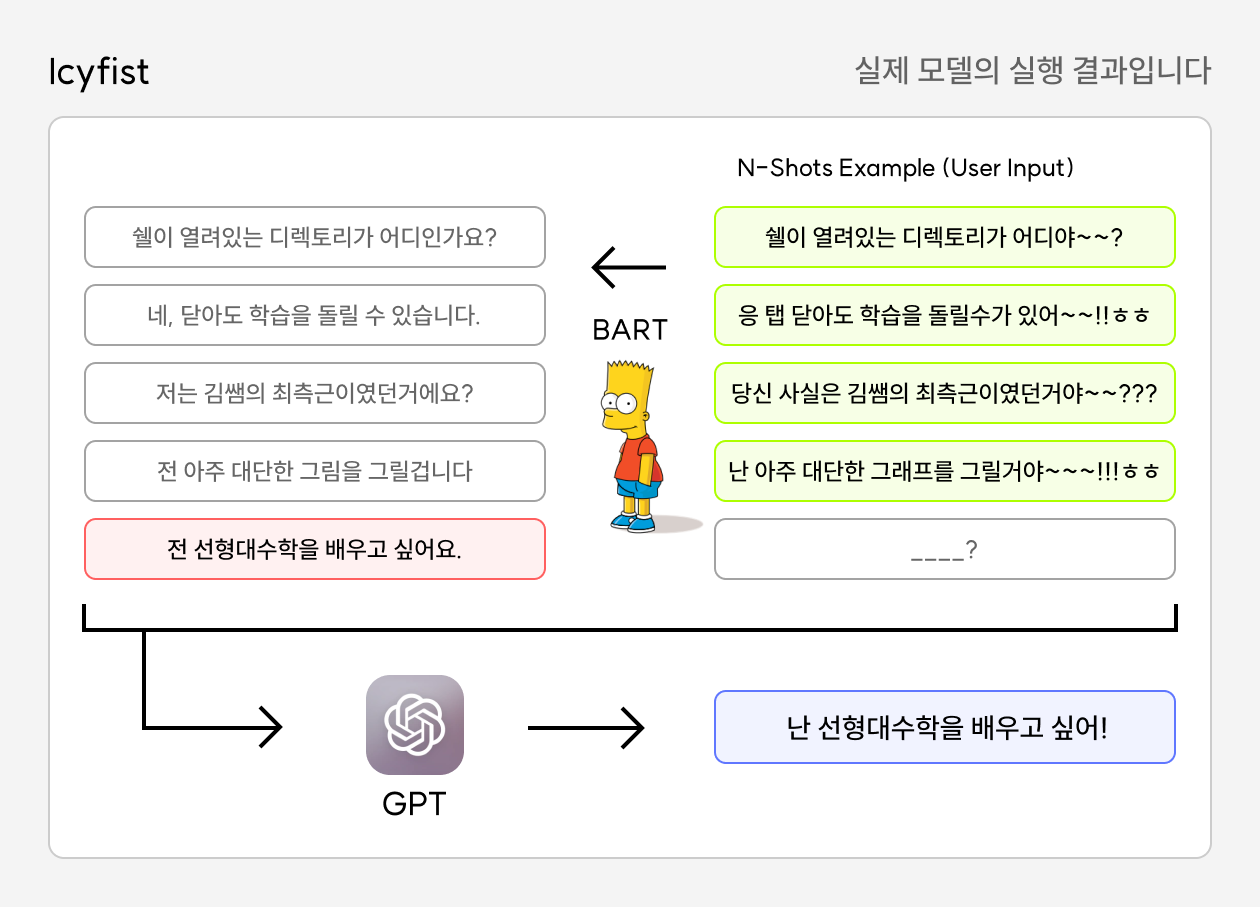
이 모델의 이름은 주요한 특징인 In-context, Few Shot, Text Style Transfer의 약자를 따서 Icyfist로 지었습니다. 몇 가지 실행 예시를 살펴보겠습니다.
# 스타일 예시 (2 Shots)
응.. 어머니가 고기를 먹고싶어 하시네.. 빨리 집에 와야될 것 같아..
아까 가게 들렀다 왔었는데.. 매출이 잘 나와서 그래도 괜찮더라고...
# 프롬프트
전 선형대수학을 배우고 싶어요.
# 결과
난 선형대수학을 배우고 싶어..
# 스타일 예시 (4 Shots)
와 대박 그 영화 완전 보고싶어졌어!!ㅋㅋ 빨리 예매하자~~ㅋㅋㅋㅋ
이게 돼?? 현실 세계에서 가능한 기술이였어??ㅋㅋㅋㅋ
21세기가 됐는데도 한 번에 잘 작동하는 프린터가 없다니....ㅜㅜㅜㅜ
이 드라마 진짜 재밌다~~!!ㅋㅋ 같이 볼래?ㅋㅋㅋ
# 프롬프트
저는 내일 떠나요.
# 결과
난 내일 떠나ㅜㅜ
---
(동일한 스타일 사용)
# 프롬프트
저는 지금 떠나면 다시 돌아오지 않을거에요. 부디 밥 잘 챙겨먹고, 제가 보고싶어도 울지 말아요.
# 결과
난 지금 떠나면 다시 돌아오지 않을거야...부디 밥 잘 챙겨먹고, 내가 보고싶어도 울지 말아!
# 스타일 예시 (4 Shots)
니가? 외국을 가? 말도 안되는 소리 마 ㅋㅋ
밥 먹었는데 뭐 어쩔건데 ㅋㅋㅋ
# 프롬프트
집에 가서 조용히 잠이나 자지 왜 관공서까지 와서 난리를 피우는지 잘 모르겠습니다.
# 결과
집에 가서 조용히 잠이나 자지 왜 관공서 와서 난리 피우는지 잘 모르겠음 ᄏᄏᄏᄏᄏᄏᄏᄏᄏᄏ
반면 구어체가 아닌 말투에서는 제대로 작동하지 않는 모습을 보입니다.
# 스타일 예시 (5 Shots)
고등학교 생기부의 예시 문체로써 학생의 대단함을 드러냄.
위와 같은 활동을 통해 능력있는 태도를 보임.
생기부 문체라는 주제로 프로젝트를 진행하고 학우들에게 발표하며 탐구정신을 보임.
조별과제를 진행하며 리더십을 보이고 주도적으로 프로젝트를 이끌어나가는 태도를 드러냄.
영어신문을 독해하는 과제를 수행하며 글로벌 리더로써의 자격을 입증함.
# 프롬프트
수업시간에 선생님께서 하신 질문들을 모아서 스크랩북을 만들었습니다.
# 결과
수업시간에 선생님이 하신 질문들을 모아서 만들었습니다.
대화체에서도 변환에 실패하는 경우가 종종 있었습니다.
# 스타일 예시 (5 Shots)
노트북 덮으시고~~ 휴대폰 넣으시고~~ 교과서를 꺼내볼까요~~
오늘 저녁 밥은~~ 뭘 먹을까요~~
싸고 맛있는~~ 과일가게에 오신걸~~ 환영합니다~~~
오늘은~~ 8월 28일이니까~~ 28번이 한번 읽어볼까요~~
8챕터 1번은~~ 이번 지필고사에 시험문제로 낼거에요~~ 참고하세요~~
# 프롬프트
다음주에 속초 가기로 한거 잊어버리지 않으셨죠?
# 결과
다음주에 속초 가기로 한거 잊어버리지 않았어?
특히 이러한 예시와 같이 문장부호까지 첨가되는 경우에는, 대체적으로 어미의 교체로만 결과가 나타나는 경향을 확인할 수 있었습니다.
모델 활용 시나리오
Icyfist를 활용하여 문체를 변환하는 가능성을 알아보았고, 실제 서비스에 어떻게 적용할 수 있을지 알아보겠습니다.
기존 챗봇 API에 연동
스캐터랩의 핑퐁이나 심심이의 SWS와 같이, 훌륭한 수준으로 공개되어있는 일생대화 챗봇들이 있습니다. 하지만 아직까지 답변 데이터셋을 수정하지 않고는, 모델의 말투를 일괄적으로 수정할 수는 없습니다(2022년 08월 기준). 이러한 모델의 앞단에 Icyfist를 결합하면, 수작업 없이도 대화 모델에게 캐릭터나 특정 사람의 말투를 적용할 수 있습니다.
사용자 맞춤 자동 응답
여러 모바일 기기 혹은 서비스에 메시지 자동 응답 기능이 탑재되어 있지만, 격식조로 문체가 통일되어있기 때문에 사용하기 부적절한 경우가 종종 생깁니다. 이러한 자동응답기에 Icyfist를 결합하면 사용자의 말투를 모방하도록 만들 수 있습니다.
참고문헌
HyperCLOVA의 활용 (3) 대화
Author: 강재욱 (네이버), 이상우 (네이버)
오픈도메인 챗봇 ‘루다’ 육아일기: 탄생부터 클로즈베타까지의 기록
Author: 김종윤 (스캐터랩)
입력 문장 Noising과 Attention 기반 비교사 한국어 문체 변환
Author: 노형종 (엔씨소프트), 이연수 (엔씨소프트)
텍스트 스타일을 바꾸는 딥러닝 기술
Author: 이수경(카카오엔터프라이즈), 이주성(카카오엔터프라이즈), 정단우(카카오엔터프라이즈)
오토인코더와 적대 네트워크를 활용한 한국어 문체 변환
Author: 양기수(고려대학교), 이동엽(고려대학교), 이찬희(고려대학교), 임희석(고려대학교)
Simple Chit-Chat based on KoBART
Author: 전희원(haven-jeon)
Simple Chit-Chat based on KoGPT2
Author: 전희원(haven-jeon)
BART: Denoising Sequence-to-Sequence Pre-training for Natural Language Generation, Translation, and Comprehension
Author: Mike Lewis, Yinhan Liu, Naman Goyal, Marjan Ghazvininejad, Abdelrahman Mohamed, Omer Levy, Ves Stoyanov, Luke Zettlemoyer