Knowledge Distillation
딥러닝 모델을 압축하는 방법은 Pruning(가지치기), Weight Sharing(가중치 공유), [Distillation](Knowledge Distillation)(지식 증류) 등 여러가지가 있습니다. 그중 본 보고서에서는 Knowledge Distillation을 통해 모델을 압축해보고자 합니다.
Knowledge Distillation이란?
Knowledge Distillation은 큰 모델을 모사하는 작은 모델을 만들어내는 압축 기법입니다. 여기서의 큰 모델을 Teacher, 작은 모델을 Student라고 합니다. GPT 모델을 학습하는 방법을 통해 Distillation을 설명해보겠습니다. GPT는 입력 시퀀스가 주어졌을 때 바로 다음 단어로 올 단어들의 확률을 맞추는 방법으로 학습을 합니다. GPT를 학습시킬 때의 입력값은 토큰의 시퀀스이고, 예측할 출력값은 다음에 올 단어의 One-hot Vector입니다.
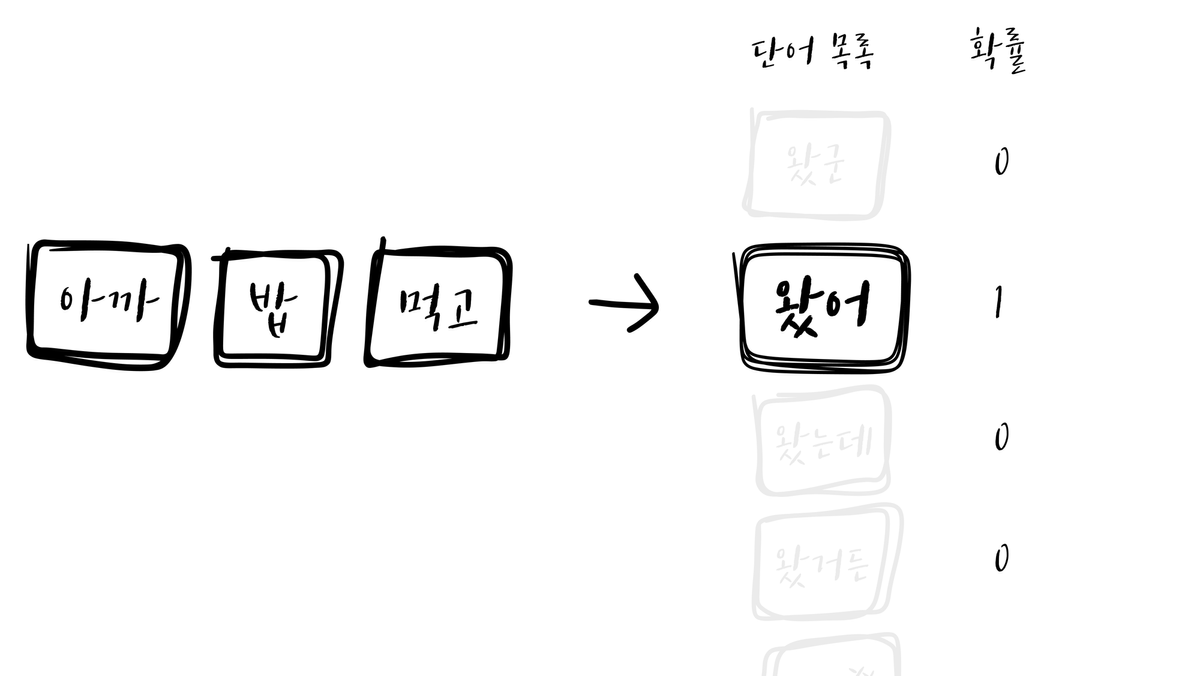
위 그림과 같이, 입력 시퀀스 다음에 제시될 단 하나의 단어만을 예측해야 할 정답으로 받습니다. 하지만 Teacher 모델이 알고 있는 언어는 위 사진과는 다릅니다.
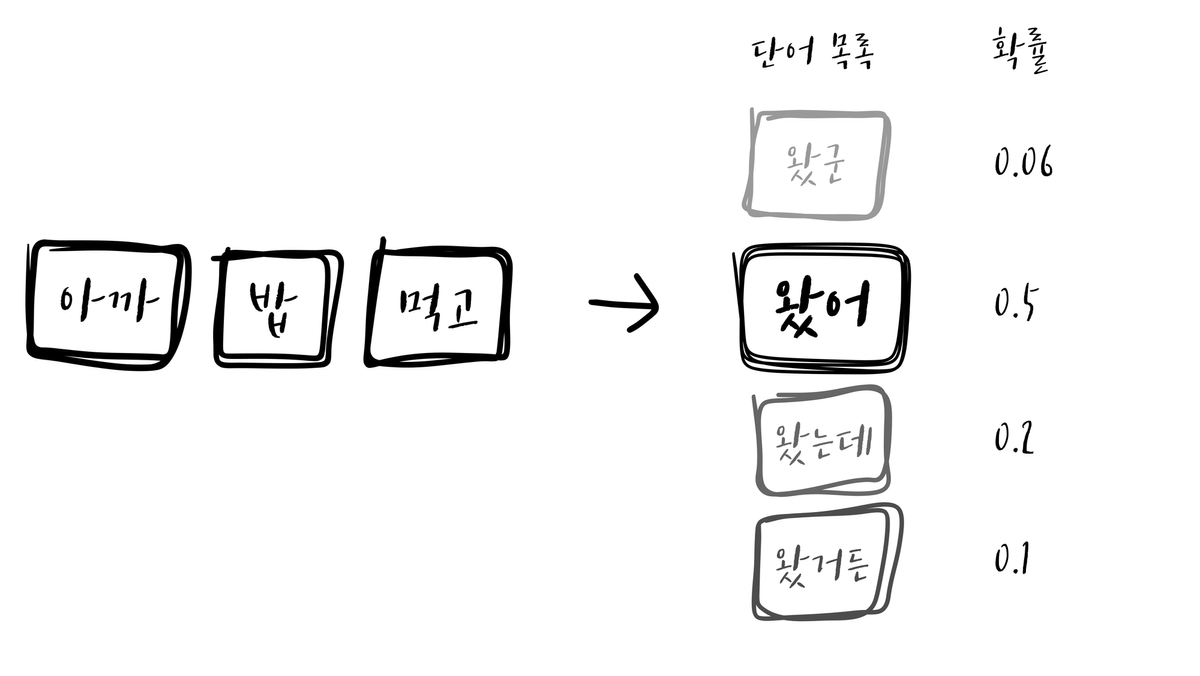
(예시를 위해 만든 이미지로, 실제 GPT 모델의 출력값과는 양상이 다릅니다)
Teacher 모델의 출력은 원핫 벡터가 아닙니다. 사전(Vocab)에 가지고 있는 모든 단어들에 대해서 등장 확률을 계산하게 됩니다. Teacher 모델의 출력값은 원핫 벡터보다 더 많은 정보를 담고 있습니다.
원핫 벡터는 “이 단어들 다음에는 A가 온다” 와 같은 이진적인 정보만 담고 있습니다. 반면 Teacher 모델의 출력값은 *“이 단어들 다음에는 A가 올 확률이 가장 높다. 하지만 작은 확률로, B나 C가 올 수도 있다”*와 같이 더 풍부한 지식을 제공합니다. Student 모델이 One hot vector 대신에 Teacher 모델의 출력값을 따라하도록 학습시키면, 더 작은 모델로도 Teacher 모델과 대등한 성능을 낼 수 있게 되는 것 입니다.
Teacher 모델의 출력을 Student에 학습시키기 위해서는, Teacher 모델의 출력을 Softmax에 넣어서 전체 사전에서 각 토큰의 등장 가능성으로 변환해야 합니다.
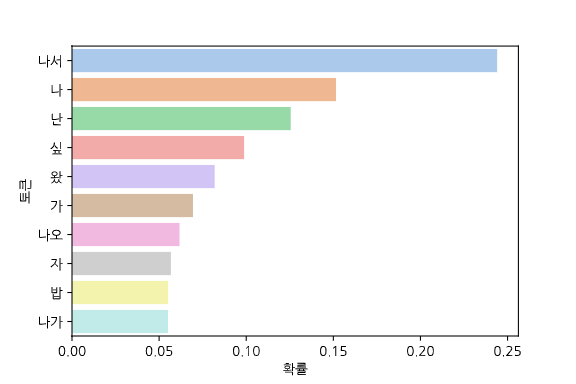
위 모습은 한국어 GPT의 출력값중 상위 확률 10개에 Softmax를 실행한 결과입니다. “아까 밥 먹고” 뒤에 “나서”가 가장 높은 확률로 나타나지만, “나”, “난”, “싶”과 같이 실제로 올법한 단어들을 제대로 예측하였습니다. 위와 같이 적절하게 확률이 분포되어있다면 Student 모델이 잘 학습할 수 있을 것 같지만, 안타깝게도 실제 결과값은 위와 다릅니다.
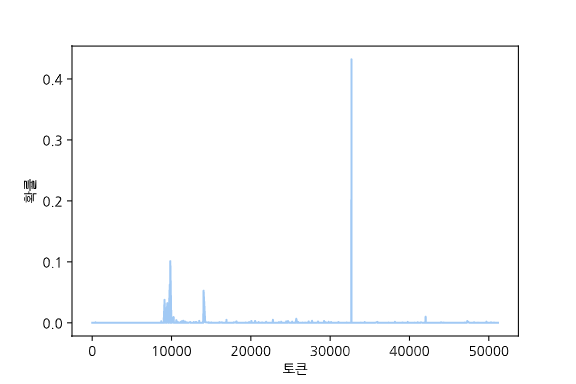
사전에 가지고 있는 모든 단어에 대해서 확률을 계산하기 때문에, 극단적인 값들이 많이 등장하게 됩니다. 물론 이 출력값을 그대로 학습시켜도 원핫벡터보다는 잘 학습할 수 있지만, 분포를 평탄하게 조정해주면 다른 토큰들의 확률을 강조하는 효과를 주어, Distillation을 더 잘 수행할 수 있습니다. 여기서 Temperature라는 개념을 사용합니다. Softmax에 들어가는 배열을 Temperature라는 일정한 수로 나눠주면, 결과값의 편차가 줄어듭니다.
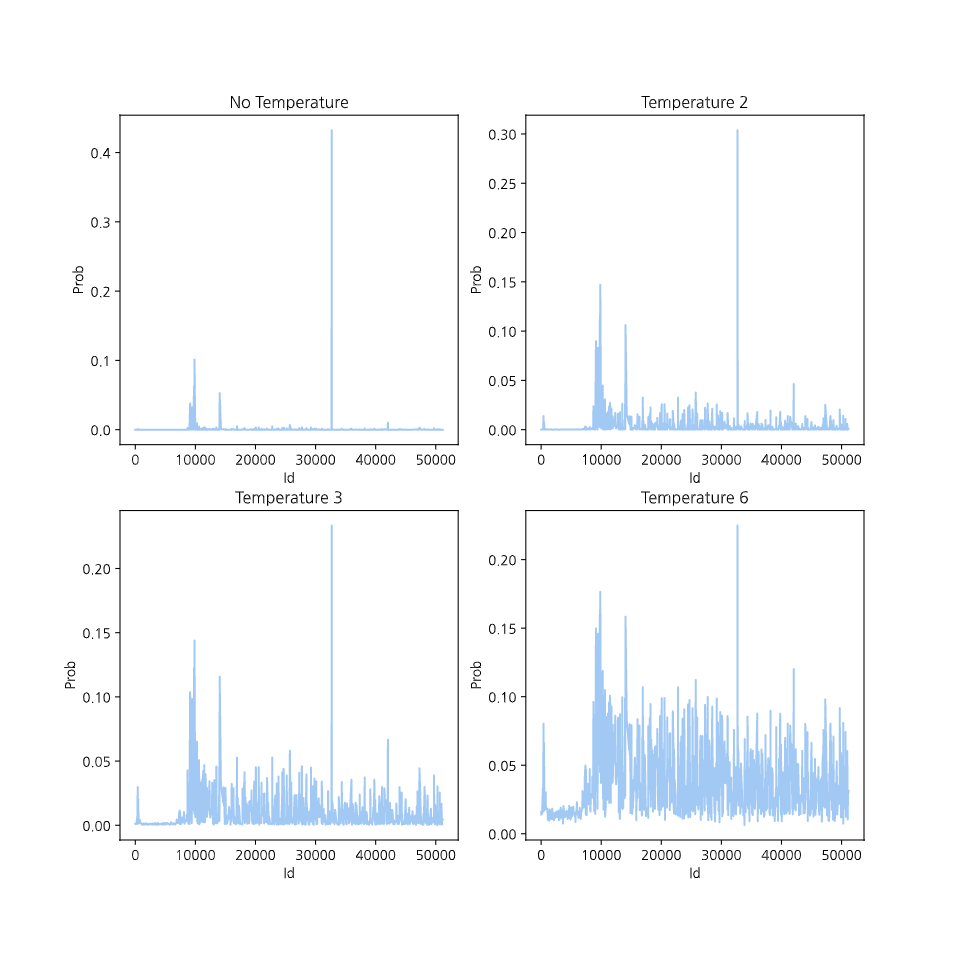
위는 각각 Temperature가 없을 때, 2일 때, 3일 때, 6일 때의 Softmax 결과(토큰별 등장확률)를 시각화한 그래프입니다. Temperature가 높아질 수록 확률의 편차가 줄어듭니다. 높았던 확률은 낮아지고 낮았던 확률은 높아져서, 모든 토큰의 등장 확률이 강조됩니다.
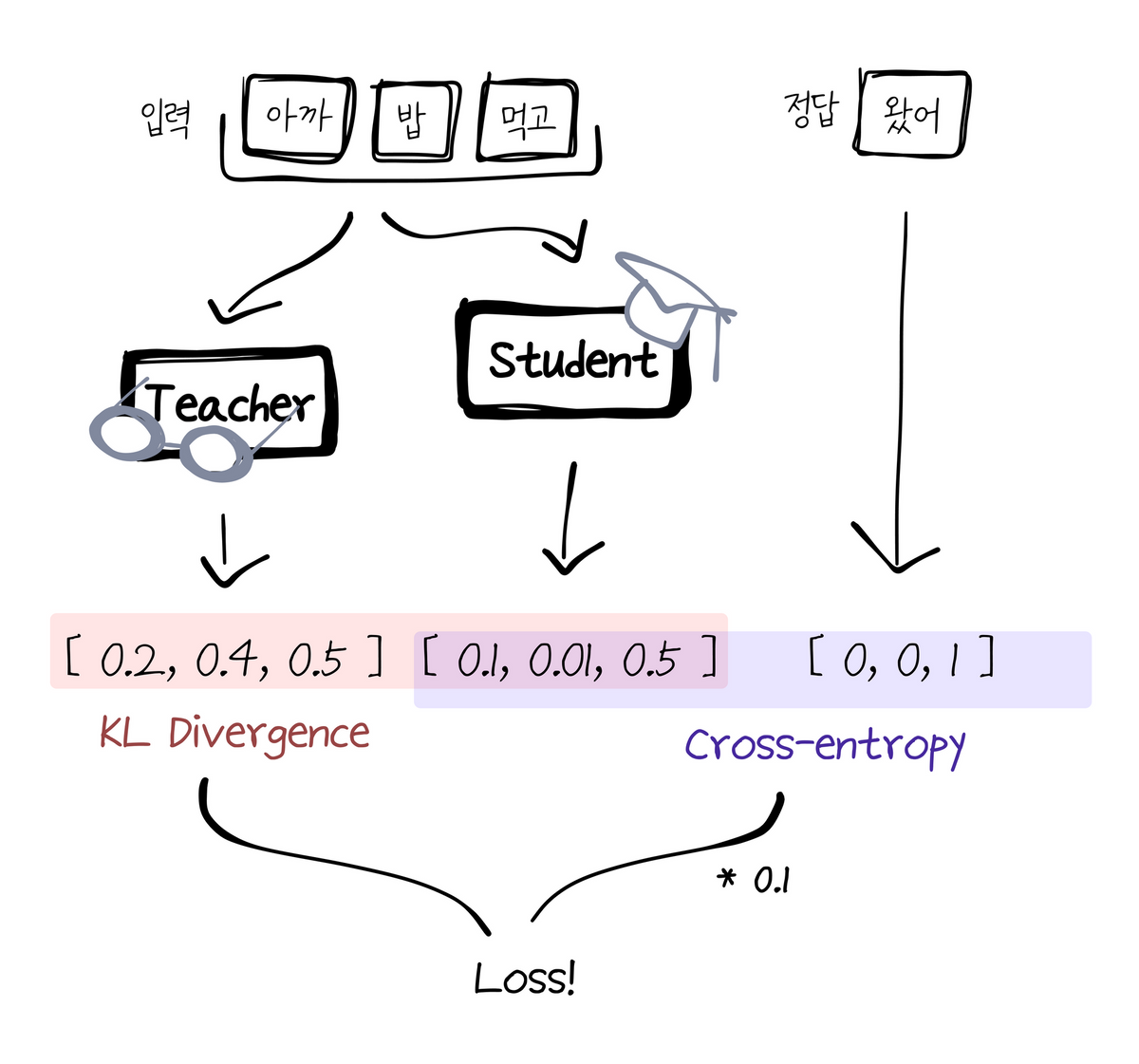
전체 모델의 동작 구조는 위와 같습니다. 동일한 시퀀스를 Student와 Teacher에 입력시키고 예측한 결과를 KL Divergence Loss로 비교해서 첫 번째 로스를 구합니다. 또한 여기에 실제 정답과의 Student 출력값의 오차 또한 Crossentropy로 비교해서 두 번째 로스를 구합니다. 여기에 두 번째 로스값에 특정한 상수값을 곱해 비중을 줄여주고, 두 로스를 더해주면 모델의 전체 로스를 구할 수 있습니다. 이러한 구조로 학습하며 Teacher의 지식을 Student에게 전달할 수 있습니다.
언어모델에서의 Knowledge Distillation 선행사례
DistilBERT
구글의 bert-base에서 레이어 수를 절반으로 줄이고 Pooling layer를 제거하여 Student 모델을 만들었습니다. 학습할 때에는 위에서 언급한 L1, L2에 더해 Student과 Teacher의 마지막 Hidden state도 Cosine embedding loss를 계산하여 추가적인 성능 향상을 이끌었습니다. BERT에 비해 크기는 40% 줄였지만(440mb → 268mb), 성능은 97%로 유지하였습니다.
- DistilBERT의 방법론을 한국어 BERT(skt/KoBERT)에 적용하여 만든 DistilKoBERT도 있습니다.
TinyBERT 4
구글의 bert-base에서 레이어 수를 12개에서 4개로 줄여서 Student 모델을 만들었습니다. L1, L2 로스에 더해 Transformer layer의 Hidden state와 Attention matrix의 오차도 계산하였으며, 성능은 96.8%로 유지하였지만 크기는 87% 줄였습니다(440mb → 62mb).
DistilGPT2
DistilBERT와 거의 동일한 방법으로 구현되었습니다. 모델 크기는 40% 감소되었으며(548mb → 353mb), 성능 감소치는 보고되지 않았습니다.
연결된 페이지 (Inlinks)
연결된 페이지가 없습니다.